Training Gym SDK
Open-source Python SDK for GRPO and RL post-training of LLMs on Modal GPU clusters — tutorials, API reference, and runnable examples.
📖 Documentation · API Reference
Modal Training Gym is a Python SDK for RL post-training on Modal—so you don’t have to hand-roll a launcher every time.
Pick a base model, a dataset, and an RL framework; the gym handles cluster topology, Ray/NCCL bring-up, volume mounts, checkpointing, and serving for eval and rollouts.
Quickstart
Section titled “Quickstart”Install with pip:
pip install -q git+https://github.com/modal-projects/training-gym.git@mainOr pin it in pyproject.toml for uv:
training-gym = { git = "https://github.com/modal-projects/training-gym.git", branch = "main" }Then import the building blocks from your own script:
from modal_training_gym import TrainConfigAgent set-up
Section titled “Agent set-up”This repository includes an AGENTS.md and a skills/ directory (symlinked to .claude/skills/) that teach Claude Code how to navigate the framework — W&B configuration, custom rollouts and generate functions, custom eval functions, and more.
Clone the repo and run claude from its root; the skills load automatically based on what you ask for.
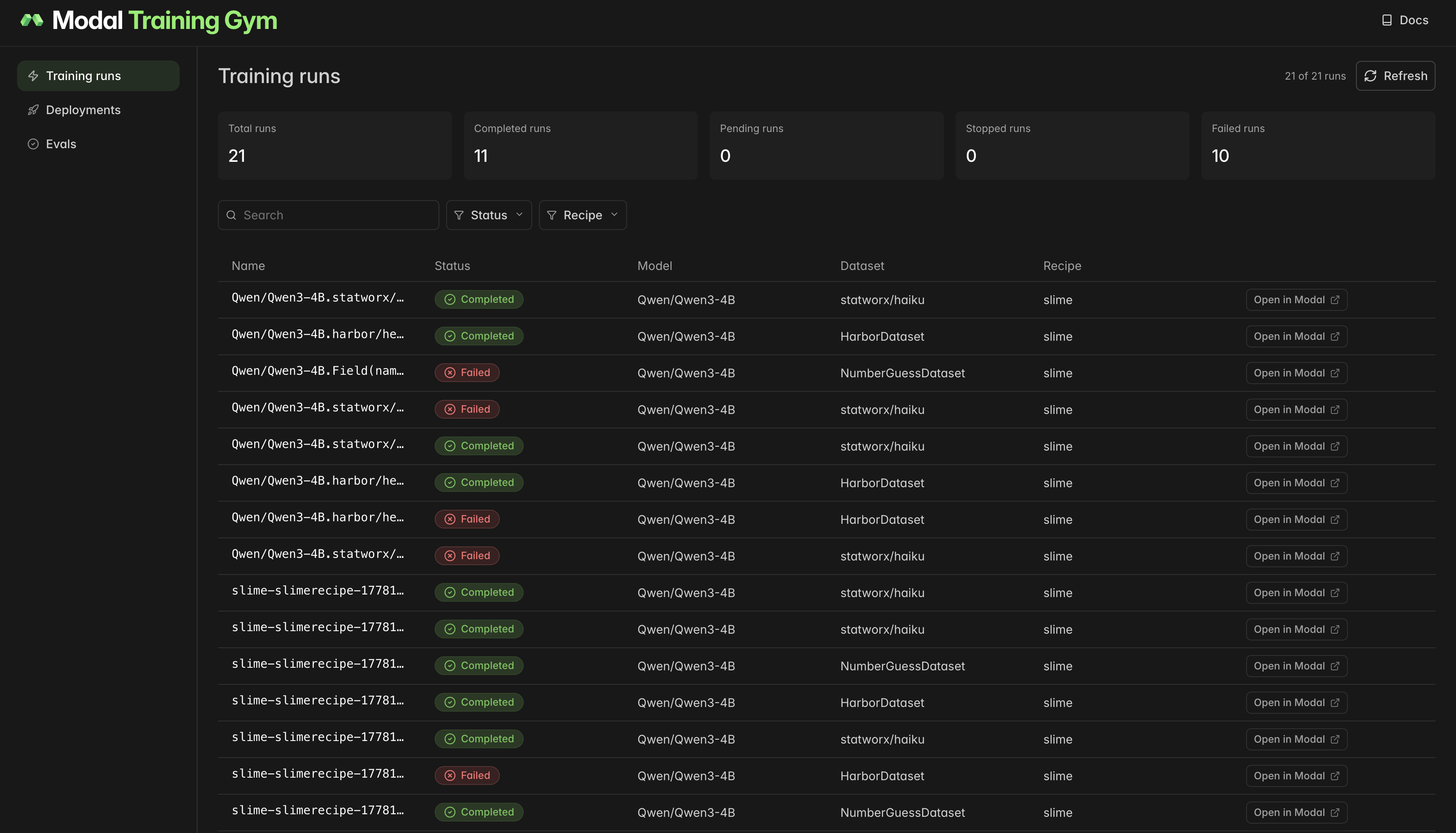
Observability dashboard
Section titled “Observability dashboard”Training Gym ships a dashboard that aggregates training runs, deployments, and eval results in one place. Deploy your own copy:
training-gym setupModal prints a URL where you can watch jobs in progress.
Tutorials
Section titled “Tutorials”The fastest path through the API is the tutorials. Each one
ships as a runnable .py and a paired .ipynb narrated cell-by-cell —
the notebook is the canonical walkthrough. Each tutorial below has a one-click
Launch button that opens the .ipynb in a fresh Modal Notebook; the first
code cell pip-installs modal-training-gym into the notebook kernel, so the
rest of the cells run as-is.
Difficulty is a rough self-assessed signal for where to start:
- Beginner — single-node, introduces one framework concept.
- Intermediate — 1–2 nodes, or wires up something non-default (custom reward, external script).
- Advanced — ≥2 nodes with non-trivial parallelism (tensor-parallel, colocated RL, long context); assumes familiarity with the underlying framework.
| Tutorial | Summary | Difficulty | Framework | Launch |
|---|---|---|---|---|
000_rl_basics | Qwen3-4B haiku evaluation with verifiable rewards — serve, evaluate, train, compare | Beginner | slime |  |
001_sandboxes | Code RL with Harbor hello-world and sandboxed verification | Intermediate | slime | |
002_multiturn | Multi-turn number-guessing RL with custom generate and reward functions | Intermediate | slime | |
003_on_policy_distillation | On-policy distillation on math — Qwen3-8B teacher, Qwen3-4B student | Intermediate | slime | |
005_dapo | DAPO on math with Qwen3-4B | Advanced | slime | |
006_audio_asr | Audio GRPO on Qwen3-ASR-1.7B — transcribe LibriSpeech, reward −WER | Intermediate | slime | |
Single Node
Section titled “Single Node”| Tutorial | Summary | Difficulty | Framework | Launch |
|---|---|---|---|---|
001_qwen27b | Train Qwen3.6-27B on DAPO-math with GRPO | Advanced | slime | |
000_qwen35b | Train Qwen3.6-35B-A3B on DAPO-math with GRPO | Advanced | slime | |
Agents
Section titled “Agents”| Tutorial | Summary | Difficulty | Framework | Launch |
|---|---|---|---|---|
000_agent_sandbox | Build an LLM agent harness with a self-hosted model and Modal Sandbox tool execution | Beginner | Modal Sandbox | |
Multinode
Section titled “Multinode”| Tutorial | Summary | Difficulty | Framework | Launch |
|---|---|---|---|---|
000_kimi_k25 | Kimi K2.5 LoRA GRPO training on 128 GPUs with DAPO-Math-17k | Advanced | miles | |
001_kimi_k26 | Kimi K2.6 LoRA GRPO training on 128 GPUs with DAPO-Math-17k | Advanced | miles | |
002_glm_4_7 | GLM-4.7 355B MoE full-weight GSPO training on 64 GPUs with DAPO-Math-17k | Advanced | slime | |
See tutorials/README.md for how to run the .py
companions from the CLI and how to author a new tutorial.
Multi-node access
Section titled “Multi-node access”Architecture
Section titled “Architecture”
Documentation
Section titled “Documentation”Full docs are hosted at gym.modal.dev:
- API Reference — every public class documented with types and defaults
Modal platform references:
License
Section titled “License”MIT.